A fintech startup I worked with a few years back had a problem most growing companies will recognize. Their payment processing platform started as a clean, well-structured monolith — a single codebase that handled user accounts, transactions, reporting, notifications, fraud detection, and about fifteen other things. For the first eighteen months, it worked beautifully.
Then it didn’t.
By the time they hit 200,000 active users, a single slow database query in the reporting module was causing checkout timeouts for customers trying to make payments. A bug fix in the notification service required deploying the entire application — which meant a 20-minute downtime window every time. Their engineering team of twelve was stepping on each other constantly. Three months into trying to hire their way out of the problem, they realized hiring more engineers into a monolith just creates more coordination overhead, not more velocity.
They migrated to microservices over eight months. By the end of that year, their deployment frequency went from twice a week to forty times a day. Checkout latency dropped 60%. And engineers could finally ship features without worrying about breaking unrelated parts of the system.
That story isn’t unique — it’s the reason microservices architecture has become the dominant pattern for scaling engineering teams and complex systems. But it’s also a story with a cautionary dimension: microservices done wrong create problems that make monoliths look appealing. This guide is about doing it right.
Understanding Microservices Architecture
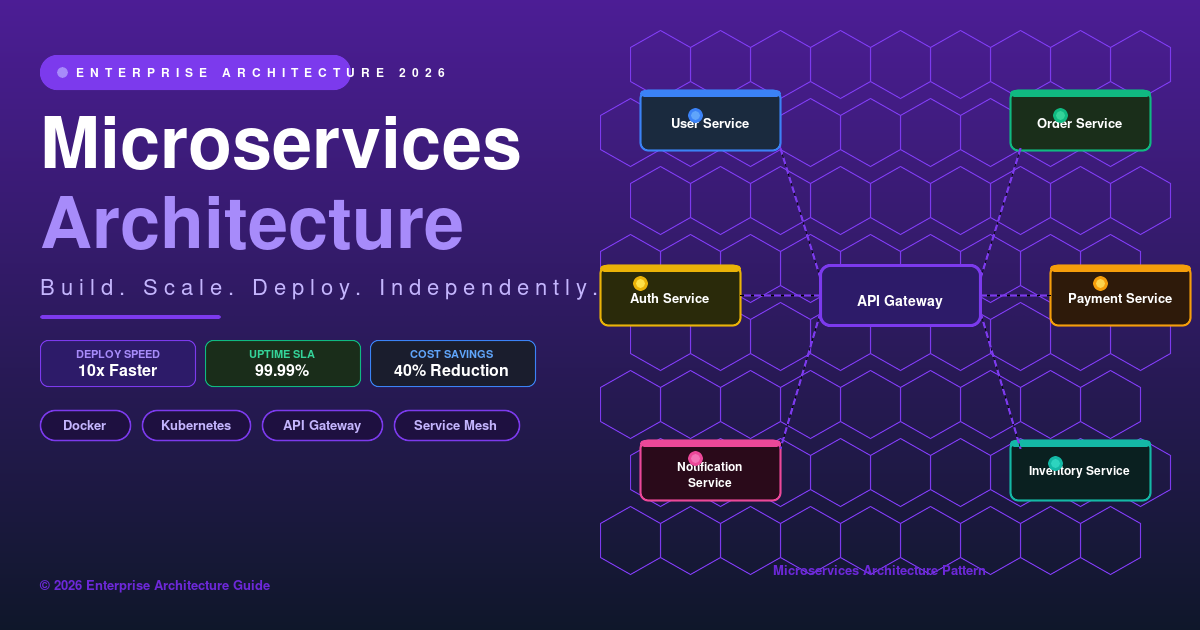
Microservices architecture is a software design approach where an application is built as a collection of small, independently deployable services, each responsible for a specific business capability and communicating over well-defined APIs.
The word “small” here is intentional but often misunderstood. A microservice isn’t defined by lines of code — it’s defined by bounded context. A User Service handles everything related to users: registration, authentication, profile management, preferences. It owns its data, exposes its APIs, and knows nothing about how the Order Service or Payment Service work internally.
This is the key distinction from a monolith, where all these functions share a codebase, a database, and a deployment unit. In a microservice architecture, each service:
- Runs in its own process
- Has its own database (or schema) — no shared databases between services
- Communicates via APIs (REST, gRPC) or messaging (Kafka, RabbitMQ)
- Can be deployed, scaled, and updated independently
- Can be written in different programming languages if needed
- Can fail without taking down the entire application
That last point is where microservices earn their place in mission-critical systems. A monolith that crashes takes everything with it. A microservices application where the Recommendation Service goes down still processes payments and serves orders.
Why Microservices Matter for Modern Businesses
The business case for microservices isn’t primarily technical — it’s organizational. The architectural shift unlocks capabilities that directly affect business outcomes.
Faster Time to Market
When each service is independently deployable, teams can ship features without coordinating releases across the entire codebase. Amazon reportedly deploys code to production every 11.7 seconds across their service fleet. That cadence is physically impossible with a monolith. For a product team competing in a fast-moving market, deployment speed is competitive advantage.
Targeted Scalability
In a monolith, scaling means scaling everything. If your search functionality needs more compute during peak traffic, you scale the entire application — including the user authentication module that has 1% of the load. With microservices, you scale the Search Service horizontally while everything else runs at normal capacity. This is why cloud costs for well-architected microservices systems are frequently 30–50% lower than equivalent monolith deployments at scale.
Technology Flexibility
One thing I’ve noticed in long-running monolith projects: the original technology choice becomes a permanent constraint. Teams are stuck on the framework, language, and database chosen in year one, even when better options emerge. Microservices allow teams to use the right tool for each job — a data-intensive analytics service running on Python with Pandas, a real-time notification service in Go, a user-facing API in Node.js.
Organizational Alignment
Conway’s Law states that “organizations design systems that mirror their own communication structure.” Microservices architecture deliberately aligns system boundaries with team boundaries. Each team owns one or more services end-to-end — from database to API to deployment. This eliminates the coordination bottleneck where every change requires approval from multiple teams.
Monolith vs Microservices: An Honest Comparison

Here’s where many teams struggle: the decision to migrate from monolith to microservices isn’t always obvious, and the internet is full of both cheerleading and horror stories. Let me give you an honest framework.
| Factor | Monolith | Microservices |
|---|---|---|
| Initial development speed | Faster — single codebase, simple setup | Slower — infrastructure overhead |
| Operational complexity | Low — one deployment unit | High — N services to manage |
| Scalability | Scale everything or nothing | Scale individual services |
| Fault isolation | One failure can cascade | Failures isolated per service |
| Team independence | All teams share codebase | Teams own independent services |
| Deployment frequency | Coupled — risk with each deploy | Independent — 10s of deploys/day |
| Technology flexibility | Locked to initial stack | Right tool for each job |
| Debugging complexity | Single trace — easier locally | Distributed tracing required |
| Best for | Early stage, small teams, MVPs | Scale, multiple teams, complex domains |
The honest answer: start with a monolith. The overhead of microservices — service discovery, distributed tracing, inter-service communication, data consistency — is real and significant. For an early-stage product or a small team, this overhead slows you down more than it helps. Migrate when the monolith becomes a genuine bottleneck, not because microservices are trendy.
Practical Rule: If your entire engineering team fits in one meeting room and your application has fewer than 20 clearly distinct domains, a well-structured monolith will outperform microservices on every business metric that matters.
Technical Deep Dive: How Microservices Actually Work
Service Communication
Services need to talk to each other, and how they communicate is one of the most consequential architectural decisions you’ll make. Two primary patterns:
Synchronous communication (REST / gRPC): Service A makes an HTTP call to Service B and waits for a response. Simple to understand, easy to debug, but creates tight coupling — if Service B is slow or down, Service A is affected. gRPC dramatically outperforms REST for internal service-to-service communication, with binary protocol (Protocol Buffers), bidirectional streaming, and built-in code generation.
Asynchronous messaging (Kafka / RabbitMQ): Service A publishes an event to a message broker. Service B subscribes to that event and processes it independently. Service A doesn’t wait — it fires and forgets. This decouples services temporally: if the Payment Service is temporarily down, the Order Service can still accept orders. Events queue up, and Payment catches up when it recovers.
In production environments, most mature microservices systems use both patterns. Synchronous calls for user-facing requests where the response is needed immediately. Asynchronous events for background processing, notifications, analytics, and workflows that don’t need an immediate answer.
Service Discovery
With dozens or hundreds of services, each potentially running multiple instances across multiple servers, how does Service A know where to find Service B? This is the service discovery problem.
Kubernetes solves this elegantly with internal DNS. Each service gets a stable DNS name (e.g., order-service.default.svc.cluster.local) regardless of which pods are running it or where they’re scheduled. No service registry to maintain — it’s infrastructure-level discovery.
Outside Kubernetes, tools like Consul, Eureka (Netflix) or etcd provide service registries where services announce their locations on startup and deregister on shutdown.
API Gateway
The API gateway is the single entry point for all external traffic. Every request from mobile apps, web apps, or third-party integrations hits the gateway first. The gateway handles:
- Authentication and authorization (validate JWT tokens before requests reach services)
- Rate limiting and throttling
- Request routing to the correct service
- SSL termination
- Request/response transformation
- Logging and monitoring at the edge
Data Management: The Hardest Part
This is where most microservices tutorials gloss over the complexity. The principle of “database per service” is non-negotiable for true service independence — shared databases create invisible coupling that defeats the purpose of the architecture. But it creates real challenges.
The Saga pattern manages distributed transactions through a sequence of local transactions, each publishing events that trigger the next step. On failure, compensating transactions undo completed steps. Complex to implement correctly, but it’s the right answer for multi-service workflows.
Eventual consistency: Data in microservices is eventually consistent, not immediately consistent. The inventory count shown on the product page may be slightly out of date. This is a business problem as much as a technical one — your product team needs to accept and design for eventual consistency.
Architecture Overview: The Full Stack

A production microservices architecture has multiple layers, each with specific responsibilities.
Client Layer
Web applications, mobile apps, and third-party integrations. All traffic originates here and hits the API gateway — never individual services directly.
Service Layer
Individual microservices, each with its own codebase, database, and deployment pipeline. Common services in e-commerce: User, Product, Order, Cart, Payment, Inventory, Notification, Search, Recommendation, Analytics.
Message Bus Layer
Apache Kafka for high-throughput event streaming (millions of events/second), RabbitMQ for lower-volume message queuing. Services publish events here; subscribers consume asynchronously.
Data Layer
Each service owns its data store, chosen for its specific access patterns:
- PostgreSQL — relational data, complex queries, ACID transactions
- MongoDB — flexible schema, document storage (product catalog, content)
- Redis — caching, session storage, real-time leaderboards
- Elasticsearch — full-text search, log aggregation
- Cassandra — time-series data, high write throughput
Service Mesh Layer
Istio or Linkerd manage service-to-service communication: mTLS encryption between services, traffic management (circuit breaking, retries, timeouts), and observability. The mesh operates as a sidecar proxy alongside each service container, transparent to application code.
Best Practices from Production Systems
These aren’t textbook recommendations — these come from watching what actually works and what doesn’t in systems serving real traffic.
Design for Failure
Every service will fail. Every network call will occasionally time out. Build for it from day one. Implement circuit breakers that stop sending requests to a failing service and return cached or degraded responses instead. Define timeouts on every external call — a hanging call without a timeout will exhaust your thread pool and cascade failures across services.
Idempotency Is Non-Negotiable
In distributed systems, network retries are automatic and frequent. An order placement API may be called twice due to a retry. If your handler isn’t idempotent, you’ll charge customers twice. Every write operation should check if it was already processed — using idempotency keys stored in Redis with TTL.
Bounded Contexts Over Chatty Services
A common mistake is creating services that are too granular. If processing a user login requires 6 synchronous service calls, you’ve created excessive network overhead and coupling. Services should encapsulate complete business capabilities, not technical layers. Prefer fewer, better-bounded services over many fine-grained ones.
Event-Driven Where Possible
Synchronous calls couple services in time. If three services need to react to a new user registration, don’t have the User Service call each one — publish a UserRegistered event to Kafka. Each interested service subscribes and processes independently. New services can be added without touching the User Service.
Version Your APIs
Services evolve. Breaking API changes break consuming services. Always version APIs from the start (/api/v1/orders) and support multiple versions simultaneously during migration windows. Never remove a version without confirming all consumers have migrated.
Common Mistakes That Kill Microservices Projects
Distributed monolith. Services that are separately deployed but tightly coupled — sharing databases, making synchronous calls in long chains, requiring coordinated deployments. This is the worst of both worlds: all the complexity of distributed systems with none of the independence benefits.
Migrating too early. Splitting a 3-month-old monolith into microservices before you understand your domain boundaries. Domain boundaries should emerge from real usage patterns, not be guessed upfront. Build the monolith first, let the boundaries reveal themselves, then extract services where independence genuinely matters.
No observability from day one. Distributed systems are impossible to debug without proper observability. Starting without distributed tracing, centralized logging, and service metrics means the first production incident takes hours instead of minutes to diagnose. Wire up observability before the first service goes live, not after the first outage.
Ignoring data consistency challenges. Assuming you can solve eventual consistency problems with “we’ll figure it out” leads to data integrity bugs that are extremely hard to fix in production. Define your consistency requirements upfront. Implement the Saga pattern for multi-service transactions.
Shared libraries as hidden coupling. Creating a shared library that multiple services depend on creates coupling through a different vector. A breaking change in the shared library requires updating and redeploying all services that use it. Prefer duplicating small amounts of code over creating shared dependencies.
Security Architecture for Microservices

Security in microservices is fundamentally different from monolith security. In a monolith, you authenticate once at the perimeter and the internal code trusts everything. In microservices, the security model is Zero Trust: every service must authenticate every request, even from internal services.
Authentication and Authorization
External authentication (API Gateway): All incoming requests from clients must carry a valid JWT token. The API gateway validates the token before forwarding the request to any service. Invalid or expired tokens are rejected at the gateway — services never see unauthenticated requests.
Service-to-service authentication (mTLS): When Service A calls Service B, both parties must authenticate using mutual TLS. Service mesh (Istio) handles mTLS transparently, rotating certificates automatically.
Authorization: JWT tokens carry claims (user ID, roles, permissions). Each service extracts claims from the token and makes local authorization decisions. No separate authorization service call per request — that would add latency and create a dependency.
Secrets Management
Database passwords, API keys, and encryption keys must never be hardcoded or stored in environment variables in plaintext. HashiCorp Vault or AWS Secrets Manager provides dynamic secrets — services request credentials at startup, credentials expire and rotate automatically. If a service is compromised, its credentials become useless quickly.
Network Segmentation
Services should only be able to reach the services they need. Kubernetes NetworkPolicies define allowed communication paths. The Payments Service should only receive calls from the Orders Service and the API Gateway — not from the Analytics Service or any other service. Principle of least privilege at the network level.
Performance Optimization Strategies
Microservices introduce inherent latency overhead — every inter-service call adds network round-trip time. Managing this well is the difference between a system that performs better than a monolith and one that performs worse.
Caching Strategy
Cache aggressively at multiple levels. Redis is the standard in-memory cache for hot data — product details, user profiles, configuration values. Cache at the API gateway level for frequently requested resources that don’t change often. Define cache invalidation strategy explicitly — event-driven cache invalidation works well in event-driven architectures.
gRPC Over REST for Internal Calls
REST with JSON is the right choice for external APIs — it’s widely supported and human-readable. For internal service-to-service calls, gRPC with Protocol Buffers is significantly more efficient: binary serialization, HTTP/2 multiplexing, bidirectional streaming. In high-throughput systems, switching internal calls from REST to gRPC can reduce latency by 30–50% and CPU usage by up to 40%.
Asynchronous Processing
Move non-critical work out of the request path. When a user places an order, the API should return a confirmation immediately, then process inventory updates, send email confirmations, and update analytics asynchronously via event queues.
Connection Pooling
Database connection overhead is significant in microservices — every service maintains its own connection pool. Use PgBouncer (PostgreSQL) or connection proxy middleware to pool and reuse connections efficiently.
Scalability: Designing for Growth
Horizontal Pod Autoscaling in Kubernetes
Kubernetes Horizontal Pod Autoscaler (HPA) monitors service metrics — CPU, memory, or custom metrics like queue depth — and automatically scales the number of pods up or down. During flash sale traffic spikes, the Cart and Checkout services scale from 3 pods to 50 pods within minutes. After the spike subsides, they scale back down.
KEDA for Event-Driven Scaling
KEDA (Kubernetes Event-Driven Autoscaling) scales services based on event queue depth — scale the order processor when the Kafka order topic has more than 1,000 unprocessed messages, scale to zero when the queue is empty. This is far more efficient for background processing workloads.
Stateless Services
Every service instance must be identical and stateless — no local state that can’t be found on any other instance. User session data goes in Redis. Uploaded files go in S3. In-progress job state goes in a database. Stateless services can scale horizontally without any special handling.
Database Scaling
Read replicas for read-heavy services. Horizontal sharding for very large datasets. CQRS (Command Query Responsibility Segregation) — separate read and write models, with writes going to PostgreSQL and reads served from denormalized Elasticsearch or Redis views optimized for query patterns.
Testing Strategy for Distributed Systems
Unit Tests
Test business logic within each service in complete isolation. Mock all dependencies — database, external APIs, message brokers. Unit tests should run in milliseconds and never touch a network. These should constitute the majority of your test suite (60–70%).
Integration Tests
Test each service with its actual dependencies — real database, real message broker, but mocked external services. Use Testcontainers to spin up real PostgreSQL, Redis, and Kafka instances in Docker for tests.
Contract Tests
Consumer-driven contract tests (Pact framework) verify that service APIs honor the contracts expected by their consumers. If Payment changes its API in a breaking way, contract tests fail before deployment. This is the most important layer unique to microservices.
Chaos Engineering
Deliberately introduce failures in production or staging — kill random service instances, introduce network latency, corrupt messages. Tools like Chaos Monkey (Netflix), LitmusChaos, or Gremlin automate this. The goal: find failure modes before your users do.
Deployment and DevOps Pipeline

The deployment pipeline for microservices needs to move fast while maintaining quality. With dozens of services potentially deploying independently every day, manual processes don’t scale.
The Pipeline
- Code commit triggers the CI pipeline (GitHub Actions, GitLab CI)
- Automated tests — unit, integration, contract tests run in parallel
- Docker image build — immutable container image tagged with Git SHA
- Security scanning — Trivy or Snyk scans the image for known vulnerabilities
- Push to registry — AWS ECR, GCR, or Docker Hub
- Deploy to staging — Helm chart update triggers Kubernetes rolling deployment
- Smoke tests — automated health checks against staging environment
- Deploy to production — canary or blue-green deployment
Deployment Strategies
Rolling deployment: Replace pods one at a time. Simple but during the update window, some users hit old pods and some hit new.
Blue-green deployment: Run two identical production environments. Switch traffic from blue (current) to green (new) atomically. Instant rollback available.
Canary deployment: Route 5% of traffic to the new version, monitor error rates and latency, gradually increase to 100% if healthy. Best of both worlds: low risk with fast rollback.
Maintenance, Monitoring and Observability

In a distributed system, “something is broken” without proper observability can take hours to diagnose. The three pillars of observability:
Metrics
Prometheus collects time-series metrics from every service — request rate, error rate, latency percentiles (P50, P95, P99), resource usage. Grafana visualizes these metrics in dashboards. Every service should expose a /metrics endpoint following the RED method: Rate, Errors, Duration.
Logs
Centralized, structured logging is non-negotiable. Every service logs in JSON format to stdout. A log aggregation stack (ELK or Datadog) collects and indexes logs across all services. Every log entry must include: service name, trace ID, span ID, user ID, and timestamp.
Distributed Tracing
When a user request touches five services, how do you know which one is slow? Distributed tracing (Jaeger, Zipkin, AWS X-Ray) propagates a trace ID through every service in the call chain. You can visualize the entire request journey and pinpoint the bottleneck exactly.
Alerting
Define alert thresholds for every critical metric: error rate above 1%, P99 latency above 2 seconds, queue depth above 10,000. PagerDuty or Opsgenie routes alerts to the on-call engineer. Alert on symptoms (user-visible problems) not causes.
Cost Considerations and ROI
| Cost Factor | Monolith | Microservices |
|---|---|---|
| Infrastructure (small scale) | Lower — single server or small cluster | Higher — N services + supporting infrastructure |
| Infrastructure (large scale) | Higher — scale everything | Lower — targeted scaling |
| DevOps tooling | Minimal | Significant (K8s, monitoring, CI/CD) |
| Team scaling cost | Increases (coordination) | Decreases (independent teams) |
The crossover point — where microservices become more cost-effective than a monolith — typically happens when you have 30+ engineers or complex scaling requirements. Before that point, the operational overhead often outweighs the benefits.
Real-World Examples: Netflix, Amazon, Uber
Netflix
Netflix operates over 700 microservices handling 200+ million subscribers globally. Their migration from a monolith (which suffered a major outage in 2008 due to a database corruption) to microservices took 7 years to complete. Their open-source contributions — Hystrix, Eureka, Zuul, Ribbon — became the foundation for much of the Java microservices ecosystem. Netflix also pioneered chaos engineering through Chaos Monkey.
Amazon
Amazon’s microservices journey preceded the term. Jeff Bezos’s famous “API mandate” (2002) required all teams to expose their data and functionality through service interfaces with no back-door access allowed. This mandate created the organizational discipline that enabled Amazon’s technical evolution into AWS.
Uber
Uber’s microservices architecture handles trip requests from 130+ countries in real time. Their dispatch system runs as independent services for matching algorithm, pricing, routing, and supply/demand estimation. Uber’s experience also yielded important lessons about microservices pitfalls — their early architecture resulted in a distributed monolith, requiring significant re-architecture work.
Case Study: E-Commerce Platform Migration
Phase 1: Identify Service Boundaries
Map the monolith’s domain model. Identify the key bounded contexts: User Management, Product Catalog, Order Management, Inventory, Payment Processing, Search, Reviews, Notifications, Analytics. These become service candidates.
Phase 2: Strangler Fig Pattern
Martin Fowler’s Strangler Fig pattern: gradually strangle the monolith by extracting services one at a time. A reverse proxy routes traffic — new services handle their domains, the monolith handles everything else. The monolith shrinks over time until it can be retired.
First extraction: Search Service. Add Elasticsearch, build a standalone service, route search traffic through the proxy.
Second extraction: Notification Service. Extract email/SMS/push notifications, adopt Kafka for event-driven triggering.
Phase 3: Infrastructure Buildout
While service extractions proceed, build the shared infrastructure: Kubernetes cluster, CI/CD pipeline for each service, centralized logging (ELK), distributed tracing (Jaeger), API gateway (Kong). Don’t start extracting services until observability is ready — you’ll be flying blind.
Results at Month 18
- Deployment frequency: 2× per week → 15× per day
- Mean time to recovery from incidents: 90 minutes → 8 minutes
- Peak traffic handling capacity: 3× improvement
- Infrastructure cost at 2× traffic: flat (targeted scaling)
- Engineering velocity: 40% improvement in feature delivery rate
Future Trends: Where Microservices Are Heading
Service Mesh Standardization
Istio and Linkerd are consolidating as the standard service mesh platforms. The service mesh is becoming infrastructure, not a choice — similar to how container orchestration went from optional to standard.
Serverless Microservices
AWS Lambda, Google Cloud Functions and Azure Functions are increasingly used to implement microservices without managing servers. For event-driven microservices with unpredictable traffic patterns, serverless is often more cost-effective than container-based services.
AI-Integrated Microservices
LLM inference services are emerging as standard microservices in enterprise architectures — search services adding semantic search via vector embeddings, recommendation services using ML models for personalization, fraud detection services incorporating real-time ML inference.
Platform Engineering and Internal Developer Platforms
At scale, the operational burden of microservices creates significant developer friction. Platform engineering teams are building Internal Developer Platforms (IDPs) that abstract this complexity. Backstage (Spotify’s open-source developer portal) is becoming the standard foundation for IDPs.
Frequently Asked Questions
How many microservices is too many?
There’s no right number — it depends on your team size and domain complexity. A rough heuristic: each service should be owned by a team of 4–8 engineers. The goal is services that match team boundaries, not an arbitrary count.
Do I need Kubernetes for microservices?
No, but it becomes increasingly practical at scale. Alternatives: AWS ECS (simpler, less flexible), AWS Lambda (serverless), Docker Swarm (simpler than Kubernetes, less powerful). Many teams start with ECS and migrate to Kubernetes as complexity grows.
How do I handle database migrations in microservices?
Each service manages its own schema migrations using tools like Flyway (Java) or Alembic (Python). For backward compatibility, follow the expand-contract pattern: first deploy a migration that adds the new column, then deploy the code that uses it, then remove the old column. Never make breaking database changes in a single deployment.
Is microservices right for a startup?
Almost always no, at the beginning. A startup’s biggest risk isn’t technical scale — it’s finding product-market fit quickly. A well-structured monolith ships features faster, is cheaper to operate, and is easier to refactor when your understanding of the domain evolves. Build microservices when team and traffic scale genuinely require it.
Key Takeaways
- Microservices solve organizational scale problems as much as technical ones — the architecture matches team boundaries to system boundaries
- Start with a monolith for new products — migrate when independence genuinely becomes a bottleneck
- No shared databases — each service owns its data, or you have a distributed monolith
- Observability first — distributed tracing, centralized logging, and metrics must be in place before services go to production
- Design for failure — circuit breakers, timeouts, retries, and idempotency are architectural requirements
- Event-driven communication where possible to decouple services in time
- Contract testing is the secret weapon for maintaining API compatibility across independent teams
- Security is Zero Trust — every service authenticates every request, including internal ones
- The cost crossover happens around 30+ engineers or significant scaling requirements
- Migration is a multi-year journey — Strangler Fig pattern, not a big-bang rewrite
Microservices architecture, done thoughtfully, creates engineering organizations that can move fast at scale — shipping features independently, scaling precisely, and recovering from failures quickly. Done poorly, it creates distributed complexity that makes everything harder. The difference between those outcomes isn’t the technology — it’s the discipline: clear service boundaries, strong observability, genuine team ownership, and realistic expectations about the operational investment required.
If you’re evaluating a migration from a monolith to microservices — or building a new platform that needs to scale — SoftwaresTech has designed and delivered microservices architectures across fintech, e-commerce, healthcare, and enterprise software. Talk to our engineering team about your specific context — we’ll give you a straight read on what makes sense for your situation and what it would realistically take to get there.
Further Reading
- API Development for Businesses Guide 2026
- Custom Software Development Guide
- DevOps Best Practices 2026
For industry benchmarks and additional context, we recommend the Microservices.io Patterns.
Need Help Building Your Next Digital Product?
From web and mobile apps to cloud infrastructure and AI-powered platforms — our engineers can help you plan, build and scale with confidence.
Related Articles
API Development for Businesses: The Complete Enterprise Integration Guide (2026)
This is the complete guide to API development for businesses — written for CTOs, engineering managers, and business owners who need to make real...

Custom Software Development: The Complete Business and Technical Guide for 2026
Everything you need to know about custom software development in 2026 — from discovery and architecture to security, DevOps, and ROI. A practical guide for business owners, CTOs, and engineering teams.
Modern Software Development Lifecycle (SDLC) Guide for 2026
How the six SDLC phases are evolving in 2026, with practical guidance on methodologies, AI-assisted coding, architecture choices, and testing.